Внутренние дубли страниц – чем опасны, как найти и обезвредить.
 Наявність внутрішніх дублів сторінок може привести до помилок індексації сайту і навіть звести нанівець результати просування. Приміром, якщо у просуває сторінки є дублі, після чергового апдейта один з них може замінити у видачі потрібну сторінку. А це зазвичай супроводжується істотним просіданням позицій, так як у дублі, на відміну від просуває сторінки, немає посилальної маси.
Наявність внутрішніх дублів сторінок може привести до помилок індексації сайту і навіть звести нанівець результати просування. Приміром, якщо у просуває сторінки є дублі, після чергового апдейта один з них може замінити у видачі потрібну сторінку. А це зазвичай супроводжується істотним просіданням позицій, так як у дублі, на відміну від просуває сторінки, немає посилальної маси.
Звідки беруться дублі сторінок?
Як я щойно згадувала, дублі бувають чіткі та нечіткі.
Чіткі дублі - це сторінки з абсолютно однаковим контентом, які мають різні URL-адреси. Наприклад, сторінка для друку та її звичайний оригінал, сторінки з ідентифікаторами сесій, одні й ті ж сторінки з різними розширеннями (. html,. php,. htm). Більшість чітких дублів генеруються движком сайту, але є й такі, які виникають через неуважність вебмастера. Наприклад, різні URL для головної сторінки - в одного нашого клієнта до недавнього часу «морда» абсолютно статичного сайту ( без движка) була доступна за трьома різними URL-адресами: site.ru /, site.ru/index.html і site.ru/default.html. Дуже часто чіткі дублі з'являються після заміни дизайну та структури сайту - всі сторінки отримують нові URL-адреси, але старі адреси теж працюють, і в результаті кожна сторінка доступна по 2 різних URL.
Нечіткі дублі - це сторінки з дуже схожим контентом:
- Де контентна частина за об'ємом набагато менше наскрізний частини : сторінки галерей (де сам зміст сторінки складається з однієї лише картинки, а решта - наскрізні блоки), сторінки товарних позицій з описом товару всього одним реченням і т. д..
- Сторінки, на яких частково (або повністю, але в різному порядку) повторюється одне і те ж зміст . Наприклад, сторінки категорій товарів в інтернет-магазинах, на яких одні й ті ж товари відсортовані за різними показниками (за ціною, за новизною, за рейтингом і т.д.) або сторінки рубрик, де перетинаються одні й ті ж товари з одними і тими ж описами. А також сторінки пошуку по сайту, сторінки з анонсами новин (якщо один і той же анонс використовується на декількох сторінках) і т.д.
Як визначити, чи є на сайті дублі?
Визначити наявність внутрішніх дублів на сайті можна за допомогою пошуку Яндекса. Для цього в пошуковому рядку в розширеному пошуку потрібно ввести шматок тексту сторінки, підозрюваної в дублях (текст потрібно вводити в лапках), вказавши в рядку «на сайті» свій домен. Всі знайдені сторінки можуть бути чіткими або нечіткими дублями один одного:
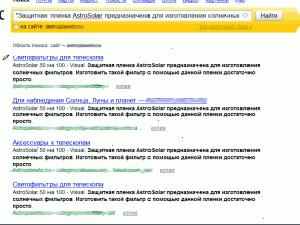
Визначити дублі можна і за допомогою пошуку Google. Для цього потрібно в пошуковий рядок ввести шматок тексту перевіряється сторінки в лапках і через пробіл вказати область пошуку - site: examplesite.ru. Приклад запиту на перевірку дублів:
"Довге предложіеніе з десяти-п'ятнадцяти слів зі сторінки, яку ми підозрюємо в тому, що у неї є дублі і хочемо підтвердити або спростувати це" site: examplesite.ru
Якщо дублі знайдуться, це буде виглядати так: 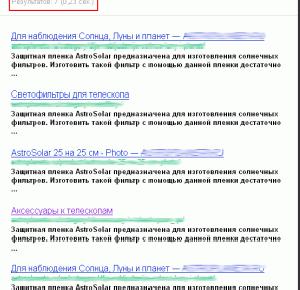
Як позбутися дублів сторінок?
Оптимальний спосіб позбавлення від дублів залежить від того, яким чином дубль з'явився на сайті і чи є необхідність залишати його в індексі (наприклад, якщо це сторінка товарної категорії або галереї).
Директива Disallow в Robots.txt
Директива "Disallow" використовується для заборони індексації сторінок пошуковими роботами і для видалення з бази вже проіндексованих сторінок. Це оптимальний варіант боротьби з дублями у випадках, якщо дубльовані сторінки знаходяться суто в конкретних директоріях або якщо структура URL дозволяє закрити багато дублів одним правилом.
Наприклад, якщо потрібно закрити всі сторінки з результатами пошуку по сайту, які знаходяться в папці www.examplesite.ru/search/, достатньо в Robots.txt прописати правило:
Disallow:/search /
Інший приклад. Якщо знак «?» Є ідентифікатором сеансу, можна заборонити індексацію всіх сторінок, що містять цей знак, одним правилом:
Disallow: /*?
Таким чином можна забороняти до індексації чіткі дублі: сторінки для друку, сторінки ідентифікаторів сесій і т.д., сторінки пошуку по сайту і т.д.
Опис директиви« Disallow »в розділі допомоги Яндекса
Опис правил блокування та видалення сторінок в довідці Google
Тег rel = canonical
Тег rel = canonical використовується для того, щоб вказати роботам, яка саме сторінка з групи дублів повинна брати участь в пошуку. Така сторінка називається канонічної .
Для того, щоб вказати роботам канонічну сторінку, необхідно на неосновних сторінках прописати її URL:
Такий спосіб порятунку від дублів відмінно підходить у тому випадку, якщо дублів досить багато, але закрити їх єдиним правилом в Robots.txt неможливо через особливості URL .
Яндекс про використання тега rel = canonical Google про атрибут rel = canonical
301 редирект
301 Permanent Redirect використовується для переадресації користувачів і пошукових роботів з однієї сторінки на іншу. Використовувати цей спосіб потрібно у випадку, якщо деякі сторінки в результаті зміни движка або структури сайту поміняли URL, і одна і та ж сторінка доступна і за старим, і за новим URL. 301 редирект дає сигнал пошуковим ботам, що сторінка назавжди змінила адресу на новий, в результаті чого вага Старий сторінки передається нової (у більшості випадків).
Налаштувати редирект з однієї сторінки на іншу можна, прописавши в файлі. htaccess таке правило:
Redirect 301/category/old-page.html http://www.melodina.ru/category/new-page.html
Можна налаштувати і масовий редирект зі сторінок одного типу на інший, але для цього потрібно, щоб у них була однакова структура URL.
Про те, як зробити 301 редірект на блозі Devaka.ru .
Творчий підхід
Бувають випадки, коли сторінки, що мають ознаки нечітких дублів, дійсно містять корисну інформацію, і видаляти їх з індексу не хотілося б. Що робити в такому випадку? Міняти, додавати або уникализировать контент.
Наприклад, якщо проблема з нечіткими дублями виникла через занадто об'ємною навігації , потрібно шукати способи збільшити контентну частину або скоротити наскрізні блоки .
Часто буває, що сторінки з описами товарів однієї і тієї ж категорії дуже схожі один на одного . Уникализировать такий текст не завжди можливо, а закривати до індексації недоцільно (це зменшує контентну частину). У цьому випадку можна порадити додавати на сторінки якісь цікаві блоки: відгуки про товар, список відмінностей від інших товарів і т.д.
У випадку, якщо в різних рубриках виводиться багато одних і тих же товарів з однаковими описами, теж можна застосувати творчий підхід . Припустимо, є інтернет-магазин сумок, де одні і ті ж товари виводяться відразу в декількох категоріях. Наприклад, жіноча шкіряна сумка з ручкою від Chanel може виводитися відразу в 4-х категоріях жіночі сумки, шкіряні сумки, сумки з ручкою і сумки Chanel. У цьому немає нічого поганого, тому що сумка дійсно підходить для всіх 4-х категорій, але якщо анонс з описом сумки виводиться у всіх цих категоріях, це може нашкодити (особливо якщо пересічних товарів багато). Вихід - або не виводити анонси на сторінках рубрик взагалі, або скорочувати їх до мінімум і автоматично змінювати опису в залежності від категорій, на яких виводиться товар.
Приклад: Стильна [жіноча] [шкіряна] Cумка чорного кольору [Chanel] [з ручкою] на кожен день.
Я зустрічала багато різних варіантів внутрішніх дублів на сайтах різної складності, але не було такої проблеми, яку не можна було б вирішити . Головне, не відкладати питання з дублями до тих пір, коли потрібні сторінки почнуть випадати з індексу і сайт стане втрачати трафік.
З ув., .
Опубліковано: 20/10/11 @ 09:12
Розділ Блоги
Рекомендуємо:
Жертвы репутации в интернете – ошибки, на которых стоит поучиться
Без ссылок нельзя…? Можно!
“В Топ за 2 дня”, или игра слов и никакого мошенничества.
10 грудня, Київ - Сіклум Java Суботник
«Недокоммунікація» як одна з ознак українського аутсорсингу