Як з'являється архітектура BI-системи
I have proved by actual trial that a letter,
that takes an hour to write, takes only about 3 minutes to read!
Lewis Carroll
Основним призначенням BI-систем є забезпечення можливості аналізу великих обсягів інформації для вирішення бізнес-завдань. Це визначає специфіку архітектури таких систем, яка спрямована на ефективне отримання, обробку та надання даних кінцевим користувачам. В укрупненому вигляді архітектуру можна представити наступним чином:
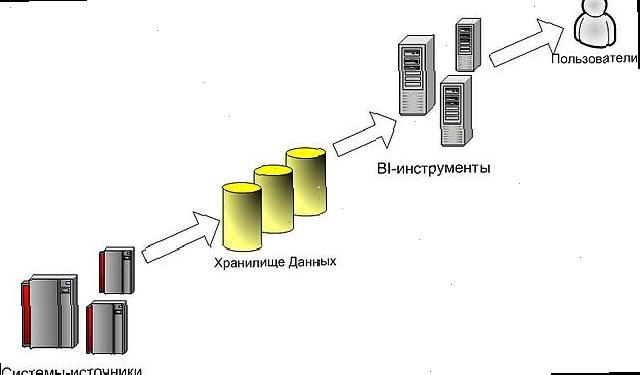
Успішність архітектури перевіряється на одне просте правило: при штатній роботі системи користувачі отримують саме ту інформацію, яка їм потрібна і саме тоді, коли вона потрібна. Коли таке правило не дотримується, це, швидше за все, означає, що аналітик і архітектор допустили помилку в момент проектування системи.
Як показує практика, архітектура, хоча б у загальних рисах, виникає вже на етапі передпродажної підготовки, після того як стають зрозумілі функціональні вимоги до майбутньої системи. Основою для створення архітектури служать дані, які потрібні для вирішення покладених на BI-систему завдань і джерела (найчастіше - різного роду облікові системи і файлові дані). При дослідженні джерел слід звернути особливу увагу на специфіку зберігання даних, регламент роботи джерела та наявність компетенцій за системою у замовника. Думаю, важливість перших двох моментів виходячи з призначення створюваної системи, інтуїтивно зрозуміла. Однак я хотів би звернути особливу увагу на компетенції замовника по експлуатованих систем. Недокументовані системи, про які замовник мало що може розповісти, завжди служать джерелом проблем і ризиків на проекті, оскільки розгляду з логікою зберігання даних в таких системах можуть тривати невизначений час, а в ході експлуатації вже створеної аналітичної системи будуть постійно виникати проблеми з отриманням даних.
Взагалі кажучи, в даний момент у світі немає єдиного погляду на архітектуру основного елемента інформаційно-аналітичних систем - Сховища Даних, в основному дискутують прихильники двох різних підходів, названих на ім'я їх авторів - Білла Інмона і Ральфа Кімбол. Якщо спробувати коротко описати їх підходи, то Інмон є прихильником створення систем з інтегрованими детальними даними, а Кімбол пропонує зосереджувати зусилля на швидкому створенні спеціалізованих вітрин даних без інтеграції всіх даних у детальному шарі. На практиці це означає, що при використанні підходу Інмона процес створення буде більш тривалим, але в підсумку система буде більш універсальна і стабільна. У разі створення сховища за методикою Кімбол ми отримаємо більш швидке рішення, яке буде не так ефективно і стійко до змін у джерелах.
Я не буду обговорювати в цій статті достоїнства і недоліки обох підходів. У моїй практиці найчастіше зустрічається ситуація, коли Замовник звертається до нас після того, як самостійно створивши «зоопарк» вітрин даних, впирається в проблеми з продуктивністю і неконсістентностью даних отриманих з різних вітрин. Відповідно, основна маса рішень, з якими я працюю, формувалася на основі підходу Інмона і мала приблизно такий вигляд:
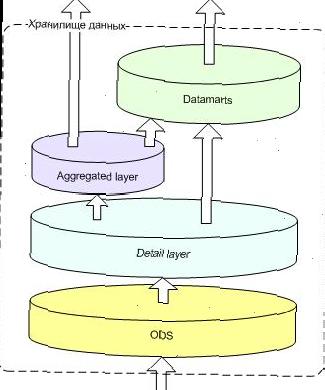
На схемі видно, що дані потрапляють у сховище через спеціальний шар - Operational Data Stage. Його призначення - мінімізувати навантаження на джерела, тому дані на цьому рівні є копіями структур на момент вилучення з джерел. Досить рідко, коли джерело не встигає видати зріз даних у відведений вікно або ж істотно перевантажений власними завданнями (таке буває з OLTP-системами у великих телекому) приходиться застосовувати механізм відстежування змінених даних, коротко - CDC. В одному з проектів нам навіть довелося розробляти власний механізм для роботи з однією з поважних версій Oracle, яку не підтримують існуючі промислові інструменти.
Отримані в ODS дані перетворюються до уніфікованого вигляду на детальному рівні. При необхідності, на етапі перетворення даних відбувається їх «очищення» - наприклад видалення дубльованих записів. Основне призначення детального рівня - зберігання інтегрованих базових даних з усіх джерел для подальшого формування вітрин і агрегованих даних у нормалізованому вигляді. По суті можна розділити всі дані на два основних типи - факти (транзакційні дані) і довідники (такі як перелік клієнтів, тарифів продуктів). Виходячи з потреб замовника і можливостей системи, для фактів визначається горизонт зберігання, найчастіше це рік чи два. Довідкові дані, як правило, зберігаються за всю наявну історію.
Для того, щоб забезпечити високу швидкість доступу користувачів до необхідної їм інформації ми завжди застосовуємо два додаткових рівня - це рівень агрегованих даних, в якому зберігаються предрассчітанние показники в необхідних розмірностях і спеціалізовані вітрини даних, такі як клієнтська вітрина, що містить в собі клієнтів з ключовими атрибутами (географічне розташування, сегмент, рівень доходу). Слід зазначити, що зараз набирає популярність дуже перспективна технологія зберігання і обробки необхідних користувачеві даних, так звана «in memory», яка, мабуть, з часом допоможе відмовитися від предрассчітанних показників, але поки це тільки перші кроки.
BI-інструменти, за допомогою яких користувачі працюють з даними, у загальну архітектуру включаються готовими блоками, в залежності від самого інструменту і особливого творчості там не потрібні. Єдиний момент, який може ускладнити життя - це інтеграція з системами Identity management. На щастя промислові BI-засоби підтримують інтеграцію з найбільш популярними системами управління ідентифікацією користувача.Що стосується вибору інструментів, на яких буде реалізована вся система, то цей момент, завжди залежить тільки від двох обставин: переваги замовника по вендорам і вендорная політика виконавця. Що я хочу цим сказати: якщо ви прийшли до замовника, у якого, приміром, придворним постачальником є ??IBM - то ніякі технічні параметри не змусять його купити СУБД Oracle. З іншого боку, якщо замовник не має явно виражених переваг, то виконавець буде пропонувати йому інструменти вендора, який запропонує виконавцю найбільш вигідні умови співпраці, простіше кажучи - велику маржу на ліцензіях. Ось приклад архітектури, продиктованою уподобаннями замовника, яка була подана на презентації бачення майбутнього проекту:
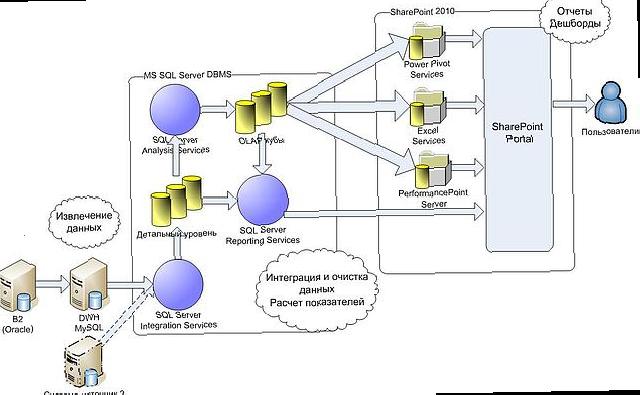
Враховуючи, що в кожному класі інструментів, які застосовуються для створення інформаційно-аналітичних систем, існує декілька фактичних рівних за своїми можливостями пропозицій від провідних вендорів, то обгрунтування вибору того чи іншого інструмента майже ніколи не грунтується на його переваги чи недоліки.
Опубліковано: 10/06/11 @ 12:21
Розділ Різне
Рекомендуємо:
Відступати нікуди: за нами - обнал
Обмін посиланнями, як засіб просування сайтів
Джерела трафіку для фарм
Особливості платіжної системи Z-Payment
Seo toolbar-и для вебмайстрів